

In the previous post, I tried to build a DQN to play the game with less than stellar results. So in this post, I'm going to try to completely revise my strategy to build a better way of solving Block Sudoku.
Revising My Approach
A game will go from turn 0 to c where c marks the turn we get the game over state. Let f(t) represent the score at a given turn t. For all x,y ∈ [0,c] such that x < y, we know that f(x) ≤ f(y) and therefore we know that f is a monotonically increasing function.
How exactly does proving that f is a monotonically increasing function help us? Well, in the past we've been targeting maximizing our score, but what if instead we tried to maximize c? That is, by prolonging the game as much as we can, by nature our score should increase (or stay the same) as c grows as well.
Since we don't know what the next batch of three blocks will be, we should place the blocks from our current queue in a way that maximizes our chances of having valid locations for placing a randomly selected new batch of three blocks.
In the last post, I mentioned using Monte Carlo Tree Searches in games. Taking inspiration from this DeepMind article (https://www.nature.com/articles/nature16961), we're going to design a tree search in the spirit of this.
Our root node will be our current state. We know that our block queue is always going to be a length of 3 and hence there are 6 different permutations where we can place them in a certain location. We can also have up to 81 different locations to place the blocks. Therefore, we can have up to 3,188,646 potential moves per turn. Since this is a crazy amount of states to evaluate each turn, we'll only analyze the first three positions for now and see how well it performs. This adds up to evaluating 162 terminal states and choosing the best one from that set.
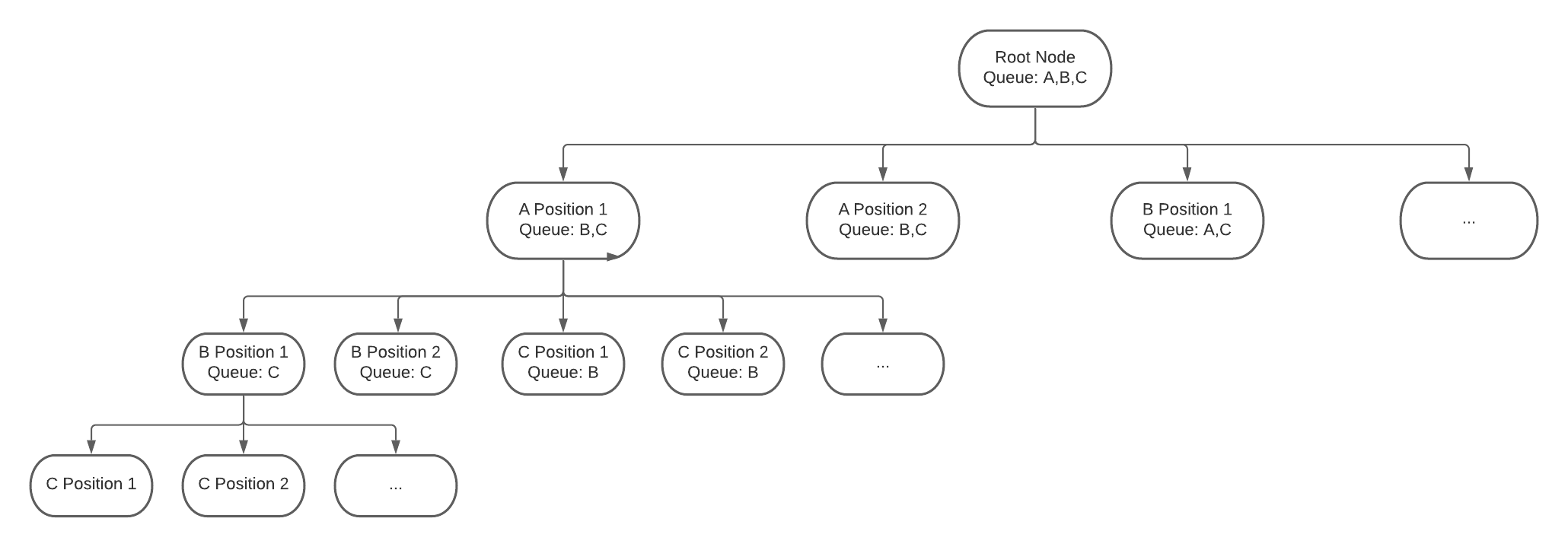
So how do we choose the best state? We can take the brute force approach and try every possible block here and see how different valid locations it can be placed. Then we can take the average of all the potential moves for every block and choose the state that gives us the highest potential moves. It may not be the best method, but it's simple and gives us a good measure of how optimal a move is. Since this is obviously an expensive operation, we may be able to replace this with a neural network later on to approximate the optimality of the move. So below is an example of how the states will be evaluated.
| Block Name | State 1 # of potential moves | State 2 # of potential moves |
|---|---|---|
| 1x1 Block | 76 | 50 |
| 1x2 Block | 57 | 38 |
| L Block | 40 | 28 |
| ... | ||
| + Block | 20 | 18 |
| Mean | 33 | 28 |
| *We prefer this end state |
But enough theory, let's write it in Python and see how it performs.
There are 162 states to calculate for iteration 0
Iteration 0 finished.
There are 162 states to calculate for iteration 1
Iteration 1 finished.
There are 162 states to calculate for iteration 2
Iteration 2 finished.
There are 23 states to calculate for iteration 3
Iteration 3 finished.
There are 30 states to calculate for iteration 4
Iteration 5 finished.
There are 126 states to calculate for iteration 6
Iteration 6 finished.
There are 0 states to calculate for iteration 7
Current game board may be impossible to solve
Game Complete
Each iteration takes about 8 seconds to compute. The bad news is that this is an O(n^3) operation so analyzing more positions will cause the algorithm to scale cubically. Here we run into an obvious scaling problem. Increasing the number of evaluated by even a small amount quickly causes each iteration to take minutes and sometimes even hours to analyze the tree. Decreasing the positions for each state to 2 so it only calculates 48 states should and does takes roughly 2 seconds to compute. Let's see how it performed.
| Trial | Random | RL | Human | Tree (3 Positions) |
|---|---|---|---|---|
| 1 | 1 | 3 | 11 | 54 |
| 2 | 0 | 10 | 5 | 32 |
| 3 | 4 | 0 | 17 | 52 |
| 4 | 1 | 4 | 19 | 11 |
| 5 | 0 | 0 | 31 | 37 |
| 6 | 1 | 0 | 20 | |
| 7 | 1 | 2 | 17 | |
| 8 | 4 | 0 | 36 | |
| 9 | 1 | 11 | 31 | |
| 10 | 1 | 0 | 32 | |
| Avg | 1 | 3 | 17 | 32 |
| Min | 0 | 0 | 5 | 11 |
| Max | 4 | 11 | 31 | 54 |
Even with only evaluating 3 positions per block combination and 162 states, we've already exceeded my performance. We're definitely on to something! I expect our score to increase as we evaluate more positions, but first we should address the performance and scaling issues we're seeing.
Reimplementing in C++ with OpenMP
So the bad news is that python is slow. It only touches about 1% of my GPU and 8% of my CPU (or 100% of one core) when running. We'd also hit a wall with the GIL if we try to multi-thread it. Here I can choose to either rework the code to run in different processes, or I could use this as an excuse to rewrite the game (yet again) in C++. I went with the latter, leveraging Eigen for my matrix operations and already the performance was night and day. Even compiling with -O0 (no compiler optimization) and debug symbols, the difference was 10-fold. Further optimizations with OpenMP and tuning led to a blazing fast simulation using 100% of all 12 cores of my Ryzen 9 processor. Suddenly, I'm able to test with 5 positions (720 states) and 10 positions (6000 states) and have it complete each iteration in the time it takes Python to evaluate 3 positions (162 states).

Let's see how analyzing 5 and 10 positions for each combination affects our scores.
| Trial | Random | RL | Human | Tree (3 Positions) | Tree (5 positions) | Tree (10 Positions) | |||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 3 | 11 | 54 | 84 | 48 | |||
| 2 | 0 | 10 | 5 | 32 | 89 | 176 | |||
| 3 | 4 | 0 | 17 | 52 | 105 | 248 | |||
| 4 | 1 | 4 | 19 | 11 | 31 | 112 | |||
| 5 | 0 | 0 | 31 | 37 | 106 | 159 | |||
| 6 | 1 | 0 | 20 | 30 | 487 | ||||
| 7 | 1 | 2 | 17 | 6 | 69 | ||||
| 8 | 4 | 0 | 36 | 75 | 88 | ||||
| 9 | 1 | 11 | 31 | 55 | 29 | ||||
| 10 | 1 | 0 | 32 | 101 | 92 | ||||
| Avg | 1 | 3 | 17 | 32 | 68 | 151 | |||
| Min | 0 | 0 | 5 | 11 | 6 | 29 | |||
| Max | 4 | 11 | 31 | 54 | 106 | 487 |
The results are impressive, far exceeding the AI and human performance. Encouraged, I decided to run it against all possible positions. This means we're testing up to 3,188,646 states per iteration which even with my optimized code, means it'll still take the better part of a day to run.
| Trial | Random | RL | Human | Tree (3 Positions) | Tree (5 positions) | Tree (10 Positions) | Tree (All Positions) | ||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 3 | 11 | 54 | 84 | 48 | 1852 | ||
| 2 | 0 | 10 | 5 | 32 | 89 | 176 | 260 | ||
| 3 | 4 | 0 | 17 | 52 | 105 | 248 | 140 | ||
| 4 | 1 | 4 | 19 | 11 | 31 | 112 | 18 | ||
| 5 | 0 | 0 | 31 | 37 | 106 | 159 | 98 | ||
| 6 | 1 | 0 | 20 | 30 | 487 | 120 | |||
| 7 | 1 | 2 | 17 | 6 | 69 | 113 | |||
| 8 | 4 | 0 | 36 | 75 | 88 | 72 | |||
| 9 | 1 | 11 | 31 | 55 | 29 | 94 | |||
| 10 | 1 | 0 | 32 | 101 | 92 | 534 | |||
| Avg | 1 | 3 | 17 | 32 | 68 | 151 | 330 | ||
| Min | 0 | 0 | 5 | 11 | 6 | 29 | 18 | ||
| Max | 4 | 11 | 31 | 54 | 106 | 487 | 1852 |
One thing to note is how wildly our results differ in variance. Even with choosing the most optimal move by our selected policy, we can get a combination of blocks that are simply unsolvable on the current board.
Conclusions
Even by taking the most optimal path, you can still end up in unwinnable states with this game. The mobile versions of the game I tried from Google Store both suffered from this flaw, meaning getting a high score is more luck based.
One way to mitigate this is allow players to regenerate their block queue once or twice after a certain number of turns if they get stuck. Of course, it's possible a player may just get screwed again. Perhaps this behavior is intended as it games may continue for way too long (or indefinitely) and the player would simply just get bored after a while.
Careful readers may have been aware that we've been skirting awfully close to the halting problem. If we were never given unsolvable states and continuously chose the most optimal end state, the game would never end and there would be no upper bounds on our score.
Regardless, I still had a lot of fun playing, implementing, and attempting to solve this game.