

Introduction
This is going to be a fairly short review of Lambda Lab's Lambda Cloud Instances. These GPU-backed instances are geared towards machine learning and AI applications, like the one I've been working on as of lately. I didn't see too many reviews out there for their cloud services, but I have seen their machines floating around in HPC clusters at school and work so I thought I'd give them a try.
Background
Most of my AI / machine learning work is as an academic student, but I also sometimes have my own personal projects that require me to rent a machine better than my school laptop. The allure of Lambda Labs to me is that it's cheaper than renting a machine from Amazon, Google, or Microsoft.
Pricing
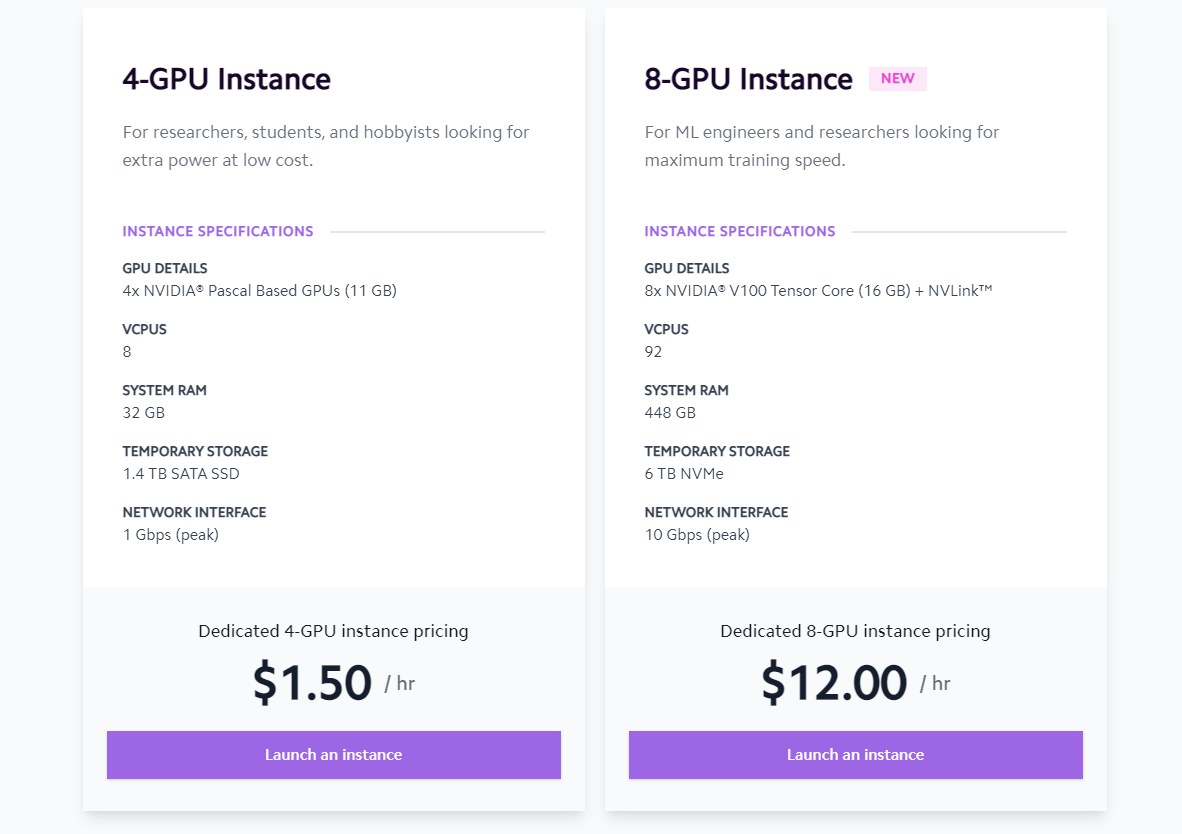
The pricing is an insanely low $1.50 /hr for a 4-GPU instance. The odd 11GB ram amount and the fact that the GPUs are Pascal-based are a pretty telltale sign that we're probably dealing with NVIDIA 1080 TIs. The 8-GPU V100 instance is only $12/hr an hour as well, beating out Amazon by a very healthy margin.
Launching an Instance
Sign-up was extremely straight-forward. Once signed in, I was required to submit my SSH keys as they only use public-key authentication for their instances. After that, I can click on "Launch Instance" and I'm provided with 5 different options.
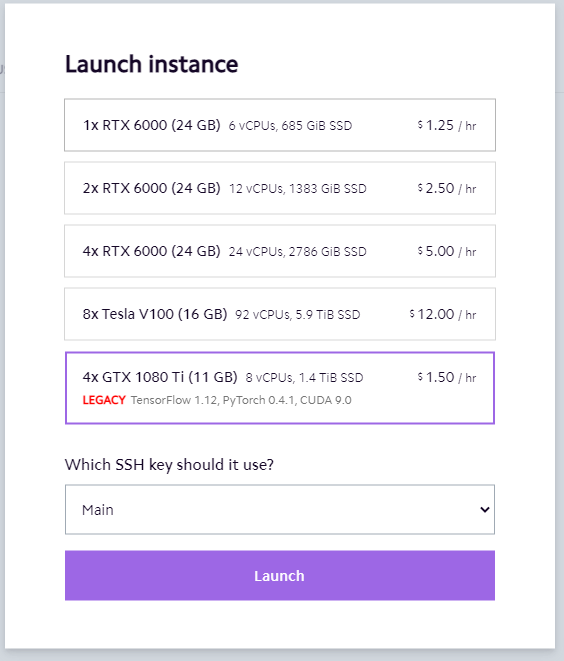
I was eager to try the first RTX 6000 based one but to my dismay it failed to launch the instance.
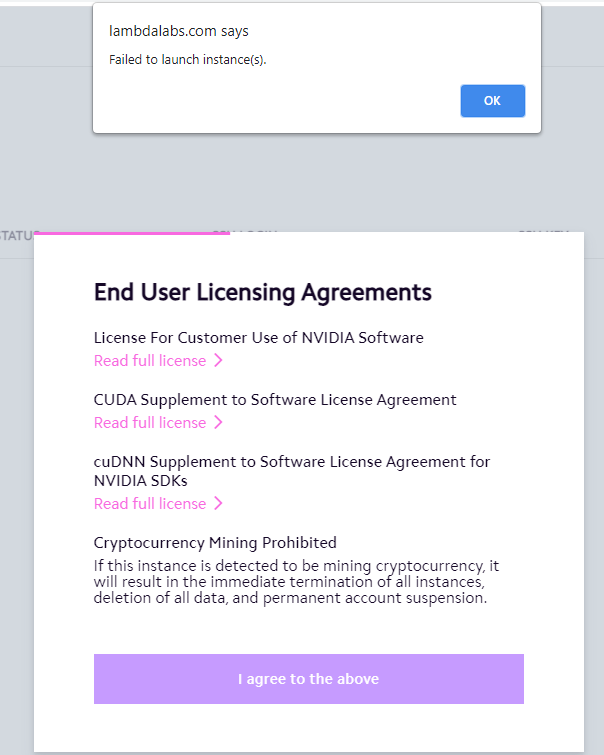
I tried the 2x/4x RTX 6000 next. Same error. I thought at this point that maybe their RTX 6000 machines were simply all being used. I tried the beefy 8x V100 they so cheeringly advertised on their front page and got the same error. Trying again throughout the current and following day resulted in the same error.
In the end I was only able to choose the Legacy labeled 1080 Ti which was honestly was too dated for any of the models I run. That was a bit frustrating, but I pressed on.
First Issue: I could only create legacy 1080 Ti instances that my models didn't even support.
Support
After a day of trying and failing to make other instances (I just assumed that maybe they were unavailable or something), I decided to give their support a shot. It's pretty easy to find it since it covers up a good part of the screen and frequently gets in the way while trying to simply navigate the dashboard.
Since it's a bit late here, the status says they'll reply tomorrow. That's fine. I type up my message.
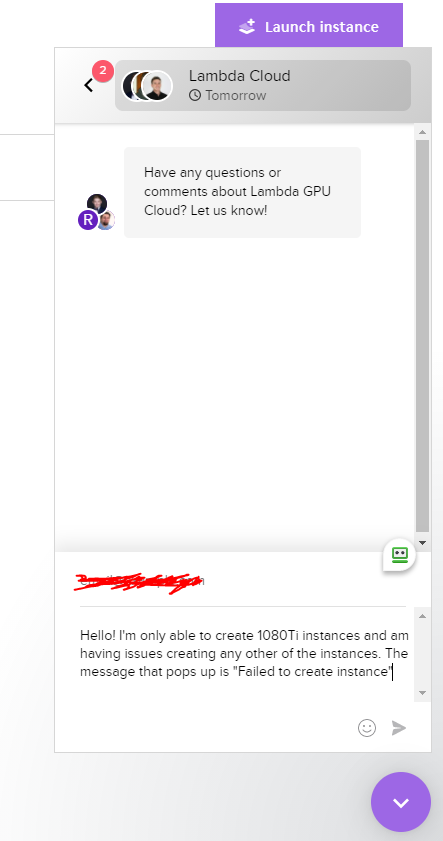
I hit send and am greeted with a loading circle that never finishes. I try again. Same issue. For how invasive their support window is, it is quite difficult to talk to them!

I'm getting a bit frustrated now, but maybe I can just reconfigure the "legacy" node they gave me to run my newer models that require things CUDA 10.2.
Second Issue: Very invasive support system despite the fact that I couldn't actually contact support.
GPU Instance Experience & Performance
The instance creation and boot-up was pretty fast and on par with other providers I've used. The first order of business was to download my models and network to the node. The network hovered around 20MiB/s which is honestly a bit slow, especially when downloading a few gigabytes of training data. Even though I'm not paying for a blazing fast network, I am paying by the hour and slow downloads cost me more money.
The second thing was to install some pre-requisite python packages through pip3. Interestingly, my whole node became agonizingly slow during this and simple shell commands were taking much longer than they should. That lag persisted even after installing the pip3 packages and I'll reiterate that I've never had this issue on other providers with the exact same script. I'm assuming that the host node my instance was on became overloaded or something. Slow sucks because again, I'm paying by the hour.
Trying to update CUDA/Nvidia on the node was an actual nightmare. I bricked the node on more than one occasion and ended up having to destroy it and relaunch a new one.
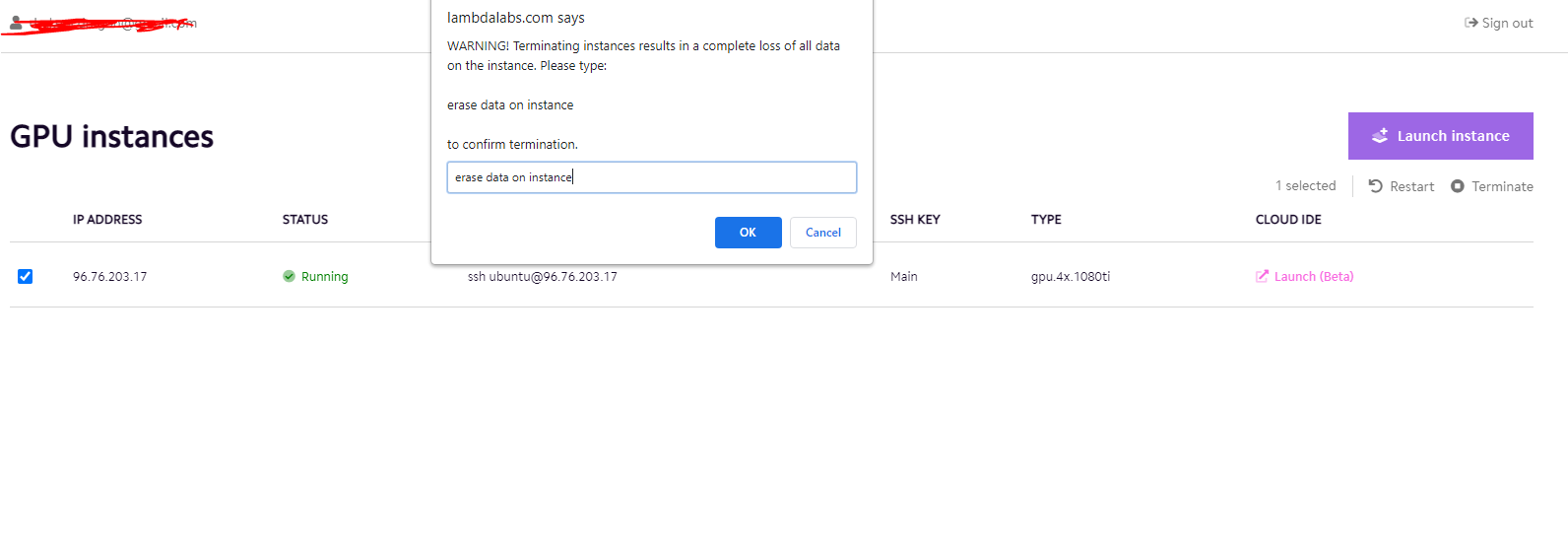
During this process, there were a lot of slow-downs in the instance that I was on. iostat, top, etc showed nothing out of the ordinary, so I assumed it was something on the hardware I was using. Still pretty annoying.
Third Issue: Performance varied wildly on my nodes. Sometimes it was blazing fast and then just suddenly became really bad. This issue persisted over different nodes.
Model Performance
I was so bitter at this point I didn't even bother to test a model. I wanted to test the ones I usually used, but the software on the "legacy" node was too dated, and it was too much of a pain in the ass to try to re-configure it. I ended up wasting more time trying to get the node working for me than actually training anything.
Pros:
- Lambda Labs is a pretty solid company for deep learning platforms and has a good reputation with the hardware they build.
- Much cheaper than Amazon, Microsoft, and Google
- Interface is very straightforward and clean.
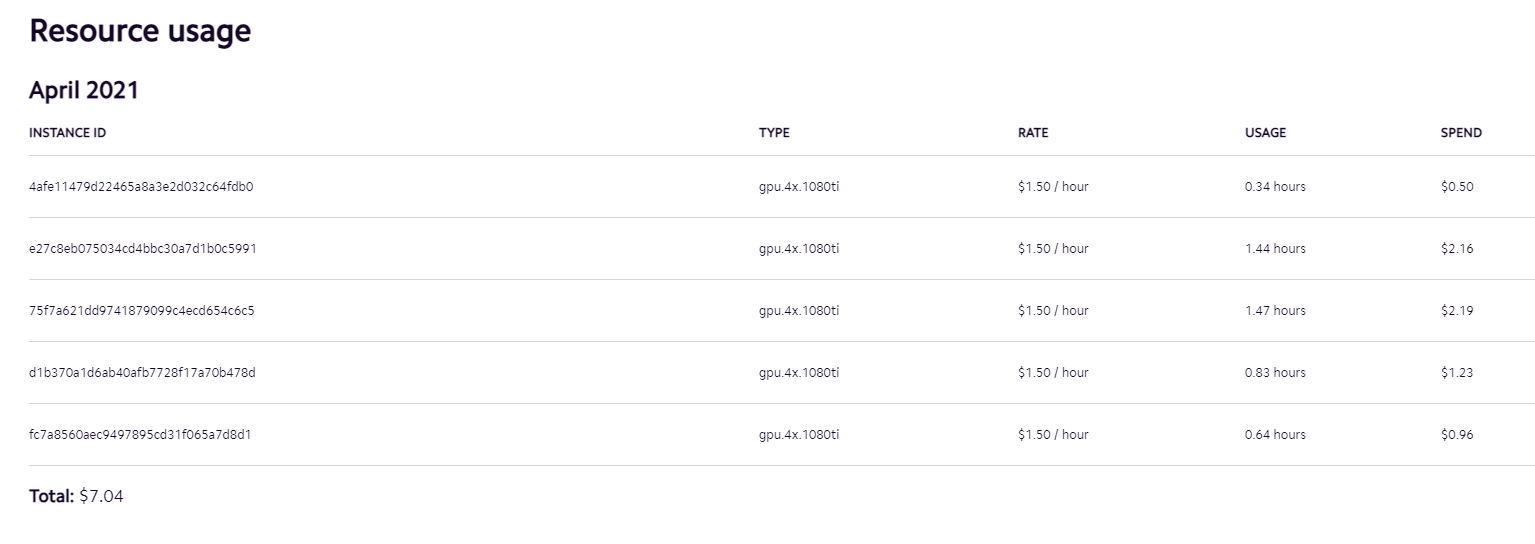
- Pricing and usage is super transparent
Cons:
- Weird performance issues with nodes
- I couldn't use any node but the legacy node and there was no explanation why.
- Re-configuring the legacy node for newer projects makes we want to pull my hair out
- Support doesn't work
- Network performance can be subpar.
Conclusion
I had an awful experience with Lambda Labs Cloud and will likely stay away from them for a while. It sounded so good on paper, but the experience was quite possibly the worst one I've had for a cloud provider. I'll likely be sticking to Microsoft for work and Amazon/Google for academic stuff.